Python进阶_字典和集合
字典
高度依赖散列表。
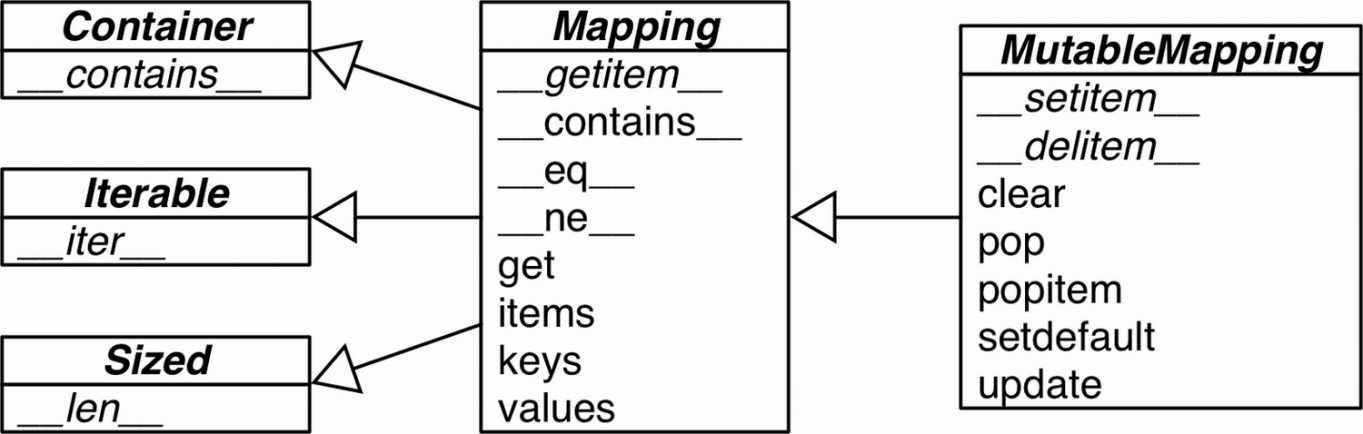
泛映射类型
collections.abc 中有 Mapping 和 MutableMapping 两个抽象基类,为 dict 和其他类似的类型定义了形式接口。
dict 继承自 object 对象,使用 __mro__ 判断方法解析顺序,可以知道 dict 的基类:
1 | >>> dict.__mro__ |
但是抽象基类能够注册虚拟子类。在 import collections 时,执行了 MutableMapping.register(),将 dict 注册成了自己的虚拟子类,因此:
1 | > from collections.abc import MutableMapping |
而Python代码版本的内置类型 dict 则实现了C代码版本的 dict 的所有接口,可以构建自己的映射类型:
1 | from collections import UserDict |
字典推导
1 | DIAL_CODES = [ |
setdefault 处理找不到的 key
快速失败理念:快速抛出异常。
d[k] 找不到正确的 key 的时候,Python会抛出异常。可以使用 d.get(k, default) 来给找不到的 key 一个默认的返回值。
1 | d = {1:2, 3:4} |
但是这样无法很好地更新或者添加键值对。
下面的例子从文本文件中统计各个单词出现的位置(开头字母的行号和列号)。将新出现的键放入字典时,涉及到了两次查询和依次列表 append 操作,代码表达力不强。
1 | import sys |
使用 setdefault 有更好的写法:
1 | my_dict.setdefault(key, []).append(new_value) |
defaultdict 为找不到的 key 创建默认值
1 | import collecitons |
default_factory只在__getitem__里调用,只能使用my_dict[key],而使用my_dict.get(key)会返回None。
特殊方法 __missing__
__missing__ 在映射类型找不到 key 的时候发挥作用,基类dict没有定义该方法。与 default_factory 相同,__missing__ 只会在 __getitem__ 中调用,对于 get 或 __contains__ 方法没有影响。
1 | class StrKeyDict0(dict): |
上述代码定义了一个用字符串作为键值的字典类 StrKeyDict0。增加了 __missing__ 方法,重写了 get 方法和 __contains__ 方法。
当使用 d[key](也即 d.__getitem__(key))时,key 找不到的情况有两种:
key是字符串但不在字典的键中;key不是字符串。
上述情况都会调用 __missing__ 方法,因此在 __missing__ 方法中,当 key 不是字符串时,转化为字符串后再进行 __getitem__ 调用。
注意,
isinstance判断是必须的,如果不判断,则产生无限递归。> graph LR > subgraph "isinstance" > C["__getitem__(key)"] --"Failed"--> D["__missing__(key)"] > D --"str"--> E["Raise ERROR"] > D --"NO str"--> F["__getitem__(str(key))"] > end > subgraph "NO isinstance" > A["__getitem__(key)"] --"Failed"--> B["__missing__(key)"] > B --"Call"--> A > end >
上述代码中,当使用 get() 方法时,查找工作实际上被委托给了 __getitem__ 方法,而 __getitem__ 又会通过 __missing__ 方法多给一次机会。
当使用 __contains__ 方法时,若传入的 key 不是字符串,那么会转化为字符串再加以判断。
不使用
k in d,反而使用k in d.keys(),这是因为前者会造成__contains__的递归调用。> graph LR > subgraph "k in d.keys()" > C["d.__contains__(key)"]--"return"--> D["k in d.keys()"] > D --"Call"--> E["d.keys().__contains__(keys)"] > end > subgraph "k in d" > A["d.__contains__(key)"]--"return"--> B["k in d"] > B --"Call"--> A > end >
Attention_1
1 | k in my_dict.keys() |
由于使用了 “Dictionary View Object”,上述查询在 Python 3 中是很快速的。
my_dict.keys() 返回的不是像 Python 2 中的列表,而是一个“视图”,类似于一个集合。
字典的变种
OrderedDict
记录添加键的顺序。使用 popitem 方法默认删除并返回字典的最后一个元素;popitem(last = False) 删除第一个添加的元素。
Python 3 中,字典的键实质上是有序的,但是基类
dict的popitem没有last参数。
ChainMap
容纳多个不同的映射对象,在执行键的查找时,这些对象会逐个被查找,直到找到为止。
能够用它作为嵌套作用域的上下文:
1 | import builtins |
Counter
计数器,可用于文章的单词计数。每次更新一个键的时候都会增加对应的计数器。
可以使用 +、- 运算符合并记录。
most_common(n) 返回前 n 个计数最多的键和它的计数。
UserDict
Python 实现的基类 dict。用于被用户自定义的子类继承。
继承 UserDict
为什么不继承
dict?主要因为内置类型的某些实现走了捷径,继承后不得不自己重写某些方法。
UserDict 是 dict 的 Python 实现,其中他有一个叫做 data 的属性是 dict 的实例,用于最终储存数据。这样做引入了新的操作对象,避免了对自身的操作,也就不会造成方法的递归。
1 | import collections |
__contains__ 和 __setitem__ 都是在对 self.data 属性进行操作,从而避免了对 self 操作造成的递归问题。
继承关系:
graph LR A["StrKeyDict"] --> B["UserDict"] --> C["MutableMapping"] --> D["Mapping"]
两个继承而来的实用方法:
MutableMapping.update:利用传入的参数构造新的实例,背后使用的是 self[key] = value。
Mapping.get :基类 dict 中,__getitem__ 会调用 __missing__ 方法,而 get 不会。但是有时候,我们希望二者的行为是一致的,都会调用 __missing__ ,这就要求我们重写 get,把具体实现委托给 __getitem__。而 Mapping.get 方法就是按照这样的思路定义的,省去了我们重写的工作。
TransformDict
不可变的映射类型
映射类型都是可变的,但是有时候我们不希望用户能够修改一个映射。可以通过 types.MappingProxyType 产生一个只读的映射视图,用户不能修改映射视图,但是原映射修改后,它的映射视图也会自动改变。
1 | from types import MappingProxyType |
集合
set 或 frozenset
空集必须写成
set(),字面量则可以写成{1, 2}
基本操作:
| 示例 | 意义 |
|---|---|
a | b |
并集 |
a & b |
交集 |
a - b |
差集 |
a ^ b |
对称差集 |
集合推导
setcomps
新建一个 Latin-1 字符集合,该集合中的每个字符的 Unicode 名字里都有 “SIGN” 单词:
1 | from unicodedata import name |
Attention_1!
unicodedata.name:获取字符的名称
集合的操作

以交集运算为例:
s & z==s.__and__(z)z & s==s.__rand__(z)==s.intersecton(it, ...)s &= z==s.__iand__(z)==s.intersection_update(it, ...)
比较运算:用偏序关系定义 >、<、>=、<=。s.isdisjoint(z)查看而这是否有共同元素。
其他功能:
s.add(e)元素添加s.clear()移除所有元素s.copy()浅复制s.discard(e)若存在元素 e,则删除s.pop()移除一个元素并返回它的值s.remove(e)若存在元素 e,则删除;若不存在,则抛出异常
效率
字典和集合的查找效率:集合交集运算 > 集合内循环查找 > 字典内循环查找 > 列表内循环查找
字典背后是散列表,相当于一个稀疏数组,每个元素叫做表元(bucket)。
Python会保证大约三分之一的表元是空的,因此超过阈值时,散列表会被复制到新的大空间内。
因此,散列表用空间换时间,内存开销巨大。
往字典中添加新键,如果需要扩容,则需要复制散列表到新空间,这一过程可能产生散列冲突,导致键的次序打乱。
同理,不要同时字典进行迭代和修改。
扫描并修改一个字典:迭代获取需要修改的内容,放入新字典;迭代结束后更新原字典。
.keys(),.items()和.values()都是返回视图,是动态变化的。